Durant cette année d'ISN, nous allons étudier l'informatique. Qu'est-ce-que l'informatique ? Le terme a été inventé en 1962 en fusionnant les mots
information et automatique par l'ingénieur français Philippe Dreyfus, travaillant chez Bull, et par le mathématicien Robert Lattès, travaillant pour la SEMA. Ils veulent à la fois donner un nom à cette
nouvelle science du traitement automatisé de l'information et à l'entreprise qu'ils sont en train de créer. De son côté, le dictionnaire Larousse donne cette définition du terme
informatique :
La science du traitement automatique et rationnel de l'information considérée comme le support des connaissances et des communications
L'ensemble des applications de cette science, mettant en œuvre des matériels (ordinateurs) et des logiciels
Plusieurs mots clefs apparaissent dans cet énoncé : traitement automatique, information, ordinateur , logiciel et enfin science. Et c'est bien parce que l'informatique est une science, jeune certes (le mot informatique n'est reconnu par l'académie française que depuis 1966), mais en plein essor qu'elle mérite d'être enseignée au lycée.
Ces informations peuvent être de natures diverses (texte, images, sons, bases de données) et la façon des les traiter peut être aussi très diverse, car les ordinateurs sont des machines universelles et pour ceux que nous étudierons, des machines déterministes.
Une suite d'instructions qui permet de traiter des informations de façon systématique, s'appelle un algorithme. Les hommes utilisent des algorithmes depuis la nuit des temps et pas seulement en mathématiques : une recette de cuisine est une forme d'algorithme ...
Pendant longtemps, la plupart des algorithmes ont été appliqués par des hommes puis par des systèmes mécaniques ou électriques de plus en plus perfectionnés. Un développement intéressant et à l'origine de l'apparition des premiers ordinateurs est celui des machines à calcul comme la Pascaline.
Le grand changement c'est l'apparition de l'ordinateur au XXième siècle, une machine universelle, dont l'architecture permet d'exécuter, de plus en plus rapidement, toute sorte d'algorithme de traitement d'informations, à condition que cet algorithme soit traduit dans un langage compréhensible par la machine.
Durant notre année d'ISN, nous découvrirons donc l'informatique à travers quatre thèmes fondamentaux :
L'ordinateur est le modèle de machine au coeur du traitement automatisé de l'information étudié par l'informatique. Le terme ordinateur a été créé en 1955, à la demande d'IBM
pour la commercialisation en France de l'IBM 650, par Jacques Perret, professeur de latin à la Sorbonne, à partir d'un mot emprunté à la théologie médiévale.
Un excellent film documentaire sur l'histoire de l'informatique a été produit en 2010 par Thierry Viéville et Gérard Berry,
il s'intitule "Pour quoi tu cherches ? : pourquoi et comment notre monde est devenu numérique" et il est disponible sur
cette page web .
Plus modestement, voici quelques dates importantes dans l'histoire de l'informatique jusqu'à l'apparition des premiers ordinateurs :
Pascal (1642) et Leibniz (1673) ont conçu au XVIIème siècle des machines capables d'additionner, soustraire voir multiplier et diviser pour celle de Leibniz.
Vers 1800, Jacquard a inventé un système de cartes perforées pour commander des métiers à tisser, les cartes agissant comme des programmes.
Les cartes de Jacquard ont donné l'idée à Charles Babbage d'imaginer une machine à calcul programmable qui constitue l'ancêtre de l'ordinateur moderne. Babbage n'a jamais pu construire sa machine mais son fils en réalisa un exemplaire vers 1910 :
Un moulin effectuait les calculs, équivalent du processeur
Un magasin stockait les résultats, équivalent de la mémoire
Les résultats pouvaient être imprimés
Les programmes étaient lus par le moulin sur des cartes perforées dans un langage spécifique que Babbage avait conçu avec Lady Ada Lovelace
Alan Turing conçut en 1936 un modèle de machine universelle de calcul, il participa aussi pendant la guerre au développement de l'énorme machine Colossus qui réussit à casser les codes secrets de la machine Enigma des Nazis.
Les premiers ordinateurs, des calculateurs géants inspirés de la machine de Babbage, furent conçus pendant la seconde guerre mondiale : le Z3 , le Mark 1, l'ENIAC.
L'ENIAC : plus de 20 m de long, 2 m 50 de haut, 30 tonnes
En 1945, John Von Neumann décrivit l'architecture d'un ordinateur et son modèle est encore celui de la plupart des machines actuelles.
Ensuite les tubes à vide et commutateurs furent remplacés par des transitors, qui furent regroupés dans des circuits intégrés, puis toute l'unité centrale fut insérée dans un microprocesseur. Ainsi les ordinateurs, d'abord utilisés par les militaires, conquirent le monde de la recherche, celui de l'entreprise puis ce fut l'essor des micro-ordinateurs (IBM/Apple) dans les années 80, celui d'internet dans les années 1990, des mobiles dans les années 2000 ...
Les trois caractéristiques fondamentales d'un ordinateur sont
qu'il est programmable , automatique et universel :
programmable : la succession des opérations qu'il peut effectuer peut être entièrement décrite par le texte d'un programme
automatique : un ordinateur peut exécuter un programme sans intervention humaine
universel un ordinateur peut exécuter n’importe quel programme
Machine de Turing
En 1936, Alan Turing a proposé un modèle de machine universelle pouvant réaliser n'importe quel calcul. Un machine de Turing est constituée d'un ruban divisé en cases (contenant des symboles comme des 0 ou des 1) le long duquel se déplace une tête de lecture/écriture. Par ailleurs il existe une table de transitions qui associent à chaque couple (état courant, caractère courant lu) un triplet (nouvel état, nouveau caractère courant écrit, déplacement de la tête). Au départ on donne à la machine une entrée, des symboles écrits sur le ruban, la machine s'exécute et elle s'arrête lorsqu'elle arrive à un couple (état courant, caractère courant lu) qui n'est pas dans la table de transition. Les symboles écrits sur le ruban constituent alors le résultat.
Une machine de Turing de base exécute à priori toujours le même programme stocké dans sa table de transition mais Turing a démontré qu'on pouvait concevoir une machine de Turing universelle qui pourrait lire sa table de transitions, son programme sur le ruban puis faire ses calculs sur une autre partie du ruban.
La machine de Turing est un modèle de calcul qui est très important en informatique théorique et en mathématiques. Turing en a d'ailleurs démontré les limites en donnant un exemple de fonction non calculable : c'est le problème de l'arrêt.
Pour mieux comprendre le fonctionnemment d'une machine de Turing , on peut consulter les documents suivants :
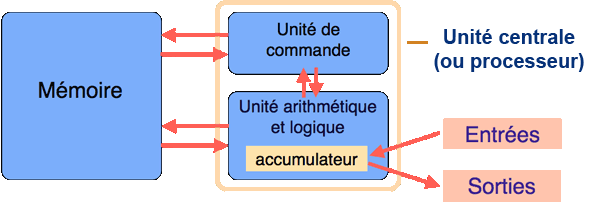
En 1945, Von Neumann participe au projet EDVAC, sucesseur de l'ENIAC et propose dans un rapport un modèle d'architecture encore valable pour les ordinateurs actuels et qui se compose de quatre éléments :
Le processeur ou unité centrale composé de deux éléments distincts :
L'unité de commande (UC) qui contrôle le séquencement des instructions
L'unité arithmétique et logique (UAL) qui exécute les instructions à l'aide d'opérations arithmétiques (addition, soustraction, mutltiplication) et logiques (ET, Ou, Non) élémentaires
La mémoire contenant les données et le programme (suite d'instructions) comme dans une machine de Turing universelle.
Des périphériques d'entrées/sorties (qui désormais peuvent être gérés par des processeurs dédiés).
L'ensemble de ces éléments communiquent par des voies d'échanges appelées bus (de données, d'adressage mémoire, de contrôle). En pratique, le débit du bus de données a cru moins vite que celui du bus d'adresses et que la vitesse des processeurs, ce qu'on appelle le goulot de Von Neumann (d'où l'utilisation de mémoires caches dans le processeur).
Le modèle de Von Neumann
Composants
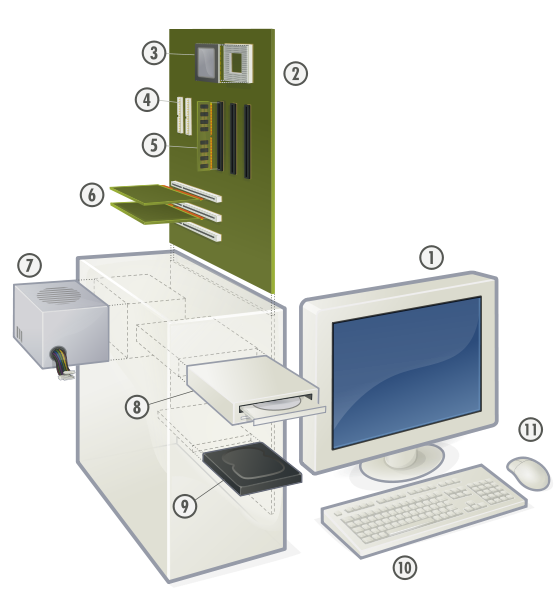
Un ordinateur moderne peut se décrire avec le schéma suivant tiré du site wikipedia.
Les composants d'un ordinateur
On peut distinguer les composants suivants :
L'écran, c'est un périphérique de sortie
La carte mère , c'est un circuit imprimé qui connecte tous les composants essentiels de l'ordinateur, sur le côté de la carte, on retrouve les ports externes (souris, clavier, ports video, ports imprimantes, ports USB, port réseau si la carte possède une carte réseau intégrée ...). la carte mère joue le rôle du bus.
Le processeur ou unité centrale, il est disposé sur un socket et surmonté d'un ventilateur et d'un dissipateur thermique (une sorte de radiateur)
Des ports Parallel ATA ou SATA pour connecter des périphériques de stockage comme des disques durs ou de lecture comme des lecteurs DVD
La mémoire vive ou RAM (Random Access Memory) qui se présente sous la forme de barettes enchâssées dans des slots. La mémoire vive est la mémoire du modèle de Von Neumann, c'est une mémoire d'accès rapide mais non persistante (les données sont effacées lorsque l'alimentation est coupée) et toutes les cellules mémoires peuvent contenir des données ou des instructions (d'où le Random Access )
Des ports PCI (Peripheral Component
Interconnect) pour des cartes d'extension (carte video, audio, réseau, carte avec ports USB supplémentaires...)
Une alimentation électrique
qui fournit une tension adaptée (5 V, 12 V) aux composants de l'ordinateur, elle est munie d'un ventilateur
Un lecteur de disque optique (DVD, CD)
Un disque dur , une mémoire de stockage externe, d'accès lent mais c'est une mémoire persistante (support magnétique).
Un clavier , c'est un périphérique d'entrée.
Une souris , c'est un périphérique d'entrée.
sous le capot
Faire une recherche sur le chipset, c'est un composant non représenté sur le schéma, mais qui est essentiel au fonctionnement de l'ordinateur.
Sur les photo suivantes ou sur la machine ouverte présentée en classe par M.Junier, reconnnaître les principaux éléments décrits ci-dessus.
Le terme information vient du latin informare qui signifie prendre forme de.
Une information est une idée qu'un esprit humain peut concevoir .Cette idée peut être associée à une représentation
du monde sensorielle (image, son) ou immatérielle (nombre, mot).
Pour représenter un type d'information on définit d'abord un système de représentation
comme le codage Rouge Vert Bleu (couleurs primaires) pour les couleurs ou les vingt six lettres de l'alphabet
pour la langue française, les notes d'une gamme musicale pour la musique, les chiffres de la numération
décimale de position ... Evidemment, plusieurs systèmes de représentation peuvent coexister :
les hommes utilisent plusieurs alphabets, les couleurs peuvent être représentées dans le système Teinte
Saturation Valeurs ...
Comme on l'a dit précédemment, un ordinateur est une machine universelle qui peut traiter
toutes sortes d'informations en leur appliquant les mêmes algorithmes génériques qu'ils s'agissent
d'informations de type images, texte ... Pour celà, on utilise en informatique, un codage universel qui est un codage à deux symboles le 0 et le 1 appelé codage binaire.
L'atome d'information est le bit et pour des raisons historiques, l'unité de cellule mémoire dans un ordinateur
est l'octet , série de 8 bits.
Toutes les informations (images, tewtes, sons) sont codées sous la forme de successions de bits mais la façon dont ils sont codés, l'encodage, diffère selon les types d'informations.
Dans les chapitres ultérieurs, nous étudierons plus en détail le codage des nombres, des caractères, des images et des sons mais une excellente introduction peut être lue dans ces pages du site Interstices : tout a un reflet numérique et codage binaire .
Codage binaire
Traiter l'exercice marquage d'oiseaux, extrait du concours Castor Informatique.
Fichiers
On a vu qu'une image, un texte, un son peut être représenté dans la mémoire vive de l'ordinateur sous la forme d'une succession de bits. Quand on a besoin de conserver des informations, on les stocke sur une mémoire persistante ou stockage de masse comme un disque dur. Sur ce disque on peut stocker plusieurs images, plusieurs textes, on a donc besoin d'organiser notre espace en une série de sous-ensembles appelés fichiers. Chaque fichier stocke une information d'un certain type (image, son, texte ...). Pour gérer les fichiers on a besoin de formater d'abord notre disque de stockage avec un système de fichiers (FAT, NTFS, ext2 ...)
systèmes de fichiers
Citer les sytèmes de fichiers utilisés par des systèmes d'exploitation tels que Windows, Linux, MacOS.
Arborescence de fichiers
En pratique le nombre de fichiers stockés dans la mémoire physique d'un ordinateur est considérable : il y a les fichiers nécessaires au fonctionnement du système d'exploitation ou des applications, ceux stockant de documents personnels (images, textes ...).
On distingue en général les fichiers normaux des fichiers exécutables. Attention le code source d'un programme en C est un fichier normal, un programme nommé compilateur permet de créer à partir du code source un fichier exécutable qui peut dépendre de la plateforme.
Les fichiers sont déjà identifiés par leur nom qui doit respecter un certain nombre de conventions pour être compatible avec plusieurs systèmes de fichiers : les caractères accentués et les espaces sont à bannir ainsi que les caractères spéciaux des systèmes ( \ sous Windows /,?,*|,-,',", sous Linux).
En plus de ses données, un certain nombre de meta-données (adresses des blocs de données, propriétaire, permissions, taille, type, nombre de leins physiques ...) sont associées à un fichier. Sous Linux, elles sont regroupées dans un structure appelée inode et tous les inodes sont gérés dans une tablea d'inodes ou FAT (File Allocation Table
Les fichiers étant très nombreux, ils sont regroupés dans des fichiers spécifiques appelés dossiers ou répertoires . Un répertoire peut être contient une liste de fichiers, en fait des pointeurs vers leurs inodes dans la FAT.
On constitue des répertoires par catégories de fichiers similaires et on peut rassembler les répertoires dans d'autres répertoires à la manière de poupées russes.
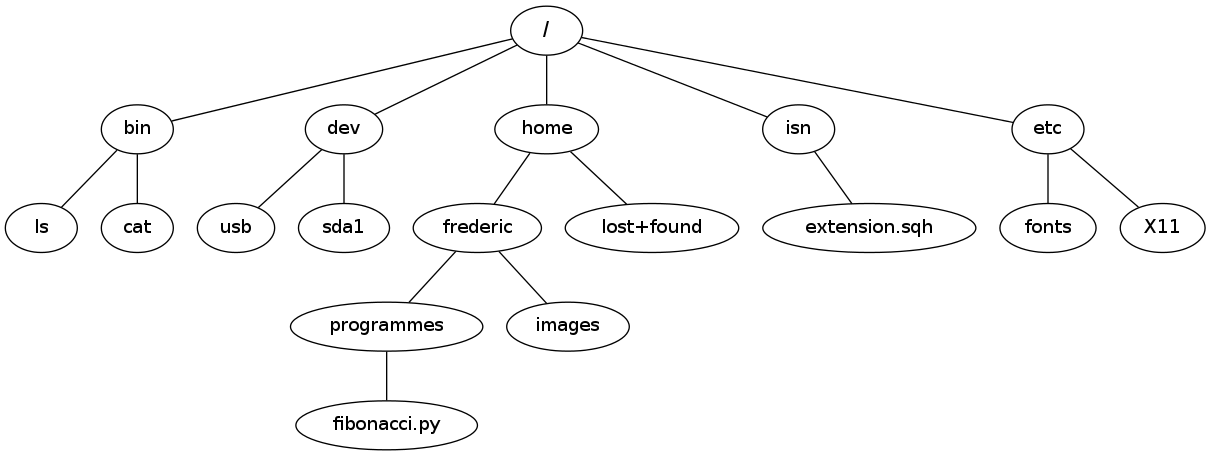
Par exemple, le dossier racine / contient le dossier home qui contient le sous-dossier frederic qui lui même contient le sous-dossier programmes qui contient le fichier fibonacci.py.
Une telle organisation des fichiers est dite arborescente, car on peut la visualiser sous la forme d’un arbre dont le répertoire racine peut s'appeler root noté / sous Linux ou \ sous Windows. Arborescence du système de fichiers sous Unix (Linux, Mac, FreeBsd ...)
Pour qu'on puisse savoir où l'on se trouve dans l'arborescence (commande pwd dans un shell Linux) chaque répertoire contient un lien vers lui-même (noté . sous Linux) et pour qu'on puisse remonter dans l'arborescence, il contient aussi un lien vers son répertoire parent (noté ..). Attention, pour maintenir une structure d'arbre, un répertoire ne peut posséder qu'un seul parent (mais il peut avoir plusieurs répertoires enfants).
Dans l'exemple précédent le fichier fibonacci.py est une feuille de l'arbre, on y parvient en partant de la racine, en suivant le tronc, puis une branche, puis une sous-branche ...
Ce chemin se note /home/frederic/programmes/fibonacci.py, c'est un chemin depuis la racine de l'arbre ou chemin absolu. Mais on peut définir aussi un chemin relatif par rapport au dossier courant (celui où l'on se trouve). Par exemple si on se trouve dans le répertoire /home/frederic le chemin relatif jusqu'au fichier fibonacci.py est programmes/fibonacci.py ou ./programmes/fibonacci.py où le symbole . désigne le répertoire courant.
Sur un même disque de stockage, un système d'exploitation peut gérer plusieurs systèmes de fichiers appelés partitions .
Linux peut intégrer dans une même arborescence des systèmes de fichiers diffếrents grace au système de fichiers virtuels VFS.
Windows fonctionne différemment en attribuant des lettres aux différents systèmes de fichiers : on peut avoir une partition système dans C:\, une partition de données dans D:\ , une clef USB dans F:\ etc ...
Voici un exemple de systèmes de fichiers montés sur un PC avec deux disques (sda sous Linux, sdb sous Windows) comportant chacun deux partitions (sans compter la partition de swap pour Linux).
Celà représente 1278493 fichiers.
Classer, sous la forme d'une arborescence, les fichiers de son répertoire personnel sur le réseau du lycée puis les fichiers que vous avez créés depuis le début de l'année dans votre dossier ISN.
Quelques commandes en mode console
La commande ls (Linux) ou dir (Windows) permet d'afficher la liste des fichiers ou sous-dossiers d'un dossier.
Les commandes du shell bash (le plus usuel sous Linux) peuvent être paramétrées avec des options introduits par des tirets hautes.
Pour connaître la syntaxe d'une commande comme ls il est recommandé de lire l'aide du manuel avec la commande man ls
user@user:~$ ls
Desktop doc.txt Documents liste
user@user:~$ man ls
user@user:~$ ls -l
total 12
drwx------ 2 user user 100 juil. 12 12:19 Desktop
drwxr-xr-x 3 user user 8192 sept. 14 21:50 Documents
-rwxr-xr-x 1 user user 85 juil. 12 04:31 liste
user@user:~$ pwd
/home/user
Comme on le voit ci-dessus la commande ls -l affiche la liste des fichiers et répertoires dans le répertoire courant
(ici /home/user, affiché par la commande pwd), avec quelques renseignements supplémentaires. Si on considère le premier bloc
de 10 caractères on trouve dans l'ordre :
en première colonne le type de fichier, - pour un fichier normal et d pour un répertoire
puis trois blocs de trois lettres rwx (ou - pour rien) indiquant les droits de lecture (r), d'écriture (w et d'exécution (c) de chaque type d'utilisateur.
Pour un fichier (ou un répertoire), il existe trois catégories d'utilisateurs : owner (le propriétaire), group (les utilisateurs appartenant au même groupe que le propriétaire) et other (tous les autres). Chaque catégorie peut disposer de droits différents en lecture, écriture et exécution. Ces principes s'appliquent sur un ordinateur personnel (avec des variantes selon l'OS), sur le réseau d'un lycée, sur un site internet ....
puis viennent le nom du propriétaire et du groupe du fichier
ensuite la taille en octets
enfin la date de la dernière modification du fichier et le nom du fichier
Tester les commandes suivantes dans une console Linux.
La commande cd (pour change directory) permet d'atteindre un fichier en donnant le chemin relatif ou absolu qui permet d'y accéder.
La commande cd .. permet d'accéder au répertoire parent et la commande pwd retourne le chemin absolu depuis la racine jusqu'au répertoire où l'on se trouve.
Le symbole ~ est un raccourci pour noter le répertoire personnel dont le chemin absolu dans cet exemple est /home/user.
La commande touch fichier permet de créer un fichier et mkdir repertoire permet de créer un répertoire.
La commande cp source cible permet de copier un fichier.
La commande rm fichier permet de supprimer un fichier et rm -Rf repertoire permet de supprimer un répertoire.
La commande ls -a affiche tous les fichiers d'un répertoire même les fichiers cachés.
Un répertoire même vide contient toujours au moins deux éléments le répertoire courant symbolisé par un . et le répertoire parent symbolisé par ..
user@user:~$ ls
Desktop Documents liste
user@user:~$ cd Documents/
user@user:~/Documents$ pwd
/home/user/Documents
user@user:~/Documents$ cd ..
user@user:~$ cd /
user@user:/$ ls
bin dev FB lib media oldroot root sbin srv tmp var
boot etc home lib64 mnt proc rr_moved selinux sys usr
user@user:/$ pwd
/
user@user:/$ cd /home/user
user@user:~$ cd /
user@user:/$ cd ~
user@user:~$ cd Documents/
user@user:~/Documents$ ls -a
. ..
user@user:~/Documents$ mkdir repertoire
user@user:~/Documents$ ls -a
. .. repertoire
user@user:~/Documents$ cd repertoire/
user@user:~/Documents/repertoire$ touch fichier.txt
user@user:~/Documents/repertoire$ ls -l
total 0
-rwxr-xr-x 1 user user 0 sept. 14 22:17 fichier.txt
user@user:~/Documents/repertoire$ cd ..
user@user:~/Documents$ touch fichier2.txt
user@user:~/Documents$ ls -l
total 8
-rwxr-xr-x 1 user user 0 sept. 14 22:40 fichier2.txt
drwxr-xr-x 2 user user 8192 sept. 14 22:40 repertoire
user@user:~/Documents$ cp repertoire/fichier.txt /home/user/fichiercopie.txt
user@user:~/Documents$ cd ~
user@user:~$ ls
Desktop Documents fichier2.txt fichiercopie.txt liste
user@user:~$ ls -R Documents/
Documents/:
fichier2.txt repertoire
Documents/repertoire:
fichier.txt
user@user:~$ cd Documents/
user@user:~/Documents$ ls
fichier2.txt repertoire
user@user:~/Documents$ rm fichier2.txt
user@user:~/Documents$ ls
repertoire
user@user:~/Documents$ rm -Rf repertoire
user@user:~/Documents$ ls
user@user:~/Documents$ ls -a
. ..
Pour plus d'infos sur les commandes de la console Linux, on pourra consulter avec profit le livre Linux l'essentiel du code et des commandes de Scott Granneman édité chez Pearson.
Exercice 6
Ouvrir une console Linux, exécuter la commande pwd, se rendre à la racine avec cd / puis la commande ls.
Utiliser la commande cd pour accéder au répertoire /usr/bin qui contient les exécutables qui ne sont pas nécessaires au démarrage du système. Exécuter la commande ls.
Exécuter la commande whereis ls qui permet de déterminer l'emplacement de la commande ls.
Uiliser la commande man pour avoir la documentation des commandes cp,zip, unzip, tar, rm (à utiliser avec la plus grande prudence),mv, touch et mkdr.
Se rendre dans le répertoire /home/user/Documents et créer un répertoire PythonScripts contenant un fichier script.py, copier ce fichier dans le répertoire /home/user puis supprimer ce fichier et le répertoire PythonScripts.
Langages
Pour écrire des programmes ou réaliser des pages web, il faut donner des instructions à l'ordinateur dans un langage. Cette année vous utiliserez deux langages :
Python qui est un langage de programmation appartenant à la famille des langages interprétés ou de script.
HTML et CSS qui ne sont pas des langages de programmation mais de description de contenu à travers sa sémantique (HTML) et sa mise en forme (CSS)
Pour réaliser votre projet, vous aurez peut être envie de créer des pages web dynamiques, je vous conseille d'utiliser alors PHP qui est un langage de script s'exécutant côté serveur et qui peut générer à la volée des pages HTML.
Algorithmes
Après avoir suffisamment programmé en Python, nous pourrons aborder quelques algorithmes classiques :